
SEMRush vs Moz Link Index Re-verified, Data Provided
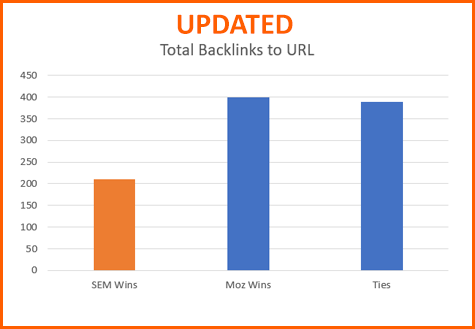
Mea Culpa: It looks like I screwed up the exported CSVs from my code below. Thank you to Malte Landwehr of SearchMetrics for finding the bizarre issues. Having an unbiased 3rd party (especially of high reputation like Malte) review is hugely helpful. Malte also identified a high % of .jobs domains in the random data set. Because some crawlers have difficulty with the new TLDs, (I am not sure if this is true of SEMRush), I limited the Domains and URLs to .org, .net, and .com. There were no meaningful changes in the outcomes of the reports EXCEPT for Total Referring Backlinks to URL, in which Moz wins 2x rather than 6x.
I often do not post data along side these mini research projects such as my most recent brief comparison of SEMRush’s link index and Moz’s for a number of reasons. The primary reason is that publishing data often comes with risk such as data rights (publishing raw data from competitors is equivalent to giving that data out for free to users). However, if I am doing a comparison piece and the one of the compared providers requests the publication of the data, that is no longer a concern.
Well, it seems that Oleg Shchegolev, CEO and Founder of SEMRush, was not confident in the results of the study and asked that I publish the data. I was out of town over the weekend, but I will happily oblige.
I will make one quick retraction. I can’t say with certainty that they remain “well behind the big 3”. Rather, all I can say given this research is they remain well behind Moz.
The first step I took was to run the experiment all over again. If the results aren’t repeatable, then they aren’t valid. As expected, the results turned out to be nearly identical to the previous test.
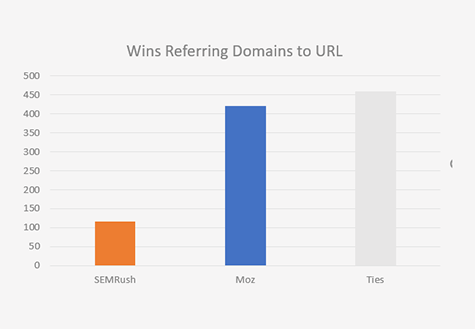
Before I show the updated graphs and the raw data, I want to make sure everyone understands the methodology. A more complete writeup is here which explains in depth how we go about getting a random sample of unique domains and URLs from the web. This is actually quite a cumbersome task and is the backbone of any successful link index comparison. Assuming you have taken the time to read the process we use to select random URLs, the second most important part of understanding the methodology is the usage of “adversarial metrics”. What I mean by an “adversarial metric” is that the scores are derived from comparing how each index performs on a particular URL or Domain one at a time. We then repeat the exercise over and over again and tally the number of wins, losses and ties between indexes. The reason why I use this methodology is as important as the methodology itself. SEOs have no use for the descriptive statistics of the index as a whole. SEOs need the most and best data they can get at a URL and domain level. It is perfectly possible to build an insanely large link index which shows no backlinks to any relevant domains or URLs if you are crawling the wrong pages. So, when you look at Moz’s index size (36 trillion links) vs a competitors, that number may be utterly meaningless to users if the index doesn’t contain their domains, their URLs and their backlinks. SEOs want to know which index is going to give them the most data about their domains and URLs.
So, in constructing an adversarial metric, we randomly select domains and URLs from the web and then determine which link index provides the most data for each of the URLs and domains, one by one. We then tally wins, losses, and ties, to identify which link index is most likely to be useful to an SEO.
The Results
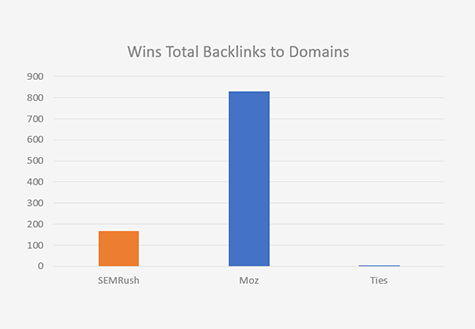
Total Backlinks to Domain
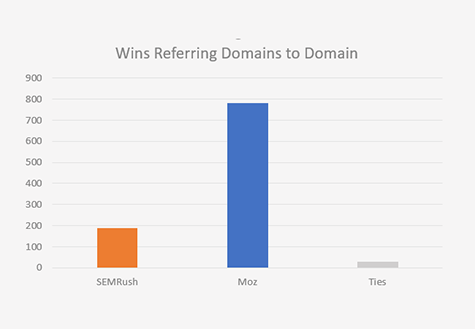
Total Referring Domains to Domain
Total Backlinks to URL
Total Referring Domains to URL
The Data
Alright, so here is the relevant data…
Note: Something is wonky about these CSVs. So, I re-ran the test AGAIN and here you go…
Concluding Thoughts
One easy test you can run is to perform descriptive statistics on the individual raw data columns in the CSVs so you can better understand the reasoning for the methodology. You will see, for example, that in Moz’s worst performing category (Referring Domains to URLs), that we only average about ~20% more referring domains to URLs. That doesn’t seem so significant, but when that difference is consistent across the network, which an adversarial metric will expose, it means that you are 4x more likely to get more data from Moz than SEMRush.
{kind=link}
Ironically I asked SEMRush to provide the 100 domains they used for this https://www.semrush.com/blog/new-semrush-backlink-database/
They ignored my email after asking me to promote the post.