
SEMRush IP Link Data Bizarre, Misleading
Disclaimer: I am Russ Jones and I work for Moz, which is a competitor of SEMRush. These are my opinions and do not represent those of Moz. That being said, the data speaks for itself.
A response from a SEMRush employee, although not speaking officially, is below.
I must admit that I was taken aback when Matthew Woodward’s recent Best Backlink Checker analysis came back so heavily in favor of SEMRush. I knew Matthew did good work and took this project seriously, vetting each provider to the best of his and his teams’ ability given the data they were provided, but it just didn’t mesh with the comparisons I run daily and weekly against Moz’s competitors. (I have spoken with Matthew about this issue and he is currently investigating independently).
Matthew’s study compared the number of unique linking IPs and Subnets reported by various link indexes across a whopping 1,000,000 domains. Unfortunately, Moz does not collect IP data, so I had to construct a conservative model to predict IP numbers. I wasn’t expecting Moz to perform well given this state of affairs. However, I certainly didn’t expect SEMRush to have grown so rapidly and dramatically in such a short time. It would have taken a technological miracle in my eyes. So I took a closer look.
Methodology
Rather than rely on the numbers reported in SEMRush’s API or tool, I collected the data myself using their own exports of root linking domains. The process was rather straightforward.
- Download list of all root linking domains
- Count Unique IPs in export.
- Compare to number in UI.
Well, here is where things get really dubious for SEMRush. [Download Raw Data]
First site: thegooglecache.com
Number of Reported Unqiue IPs: 859
Actual Based on Root Linking Domains: 636
Discrepancy: +25%
Second site: matthewwoodward.co.uk
Number of Reported Unqiue IPs: 7700
Actual Based on Root Linking Domains: 5669
Discrepancy: +26%
Third site: grepwords.com
Number of Reported Unqiue IPs: 551
Actual Based on Root Linking Domains: 436
Discrepancy: +21%
These were just the first 3 sites that I tested. Obviously this was disconcerting, so I decided to dig deeper just within the app. The picture is not pretty.
First, SEMRush shows IP addresses which are reported as linking to a domain in the IP address tab that are not in fact tied to a domain in their system. That is to say, SEMRush reports that a domain has a link from a certain IP, when you click on the IP to find the domain it is assigned to, SEMRush reports “Not Found”.
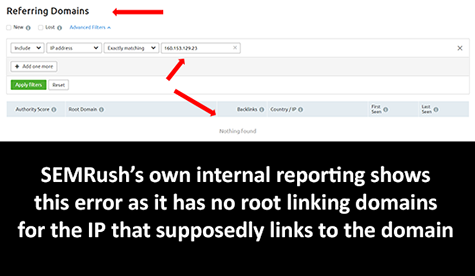
Second, there are thousands of instances where SEMRush reports more unique IPs than domains.
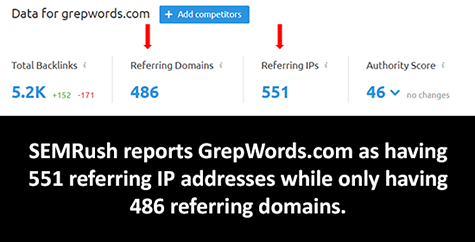
In fact, a test of ~3600 random domains yielded approximately 70% with more IPs than domains. The complete [csv can be downloaded here]
So, what is going on here. Is SEMRush outright falsifying data?
I don’t think so. What I think is going on is an issue of how SEMRush stores IPs at a link level rather than a domain level. This means that if they visit a site that uses a round robin DNS to load balance, they could get multiple IP addresses for the same domain. While services like Majestic and Ahrefs likely store a single canonical IP address per domain, SEMRush seems to store per link, which accounts for why there would be more IPs that referring domains in some cases. I do not think SEMRush is intentionally inflating their numbers, I think they are storing the data in a different way than competitors which results in a number that is higher and potentially misleading, but not due to ill intent.
What does this mean for users?
If my intuition is correct, the number of unique IP addresses is not a safe metric to use in SEMRush. If your site has a sitewide link from a website that has a round-robin DNS, you could accumulate dozens if not hundreds of unique IPs based on the crawl of that site and the number of IPs across which the site is load balanced. Whereas another site, with a similar sitewide link from a website with no round-robin DNS would report only 1 IP address. Furthermore, comparing IP and Subnet counts between providers (Moz, Ahrefs, Majestic, SEMRush, Spyglass, etc.) is not an apples-to-apples measurement unless and until SEMRush changes their collection or reporting methods.
Important Takeaways
I have repeated this many times before, but it is worth repeating again. Ask your data providers how they collect, store, and report on metrics. Teasing out the differences between providers is essential to making fair comparisons and determining what might be best for you and your team. This IP address issue is just one of many difficult questions that companies which crawl the web must answer, and the way they answer these questions can dramatically change reporting.
Also, I want to point out the importance of research like that done by Matthew Woodward. If he had not run this extensive analysis, you and I and the rest of the community may never have noticed this important distinction. And, in missing this distinction, we would be potentially misled by our assumptions on what particular metrics mean. We need you, the independent SEOs of this world, to keep our feet to the fire (Moz included).
{kind=link}
Hi Russ,
I am Olga Andrienko and I work for SEMrush, which is a competitor of Moz. These are my opinions and they do represent those of SEMrush.
The SEO tools industry had always been known for the respect among the members of our vast community. I believe it’s a space full of true professionals working together to ensure marketers have the best tools to deliver results. We have always spoken highly of our competitors, including Moz, and when the Moz was a market leader it was an inspiring challenging time to look up to you guys.
What I definitely wasn’t expecting from any Moz employee is the yellow press type headlines and incorrect data published about us.
In your methodology, you were looking at unique IPs. You should have used the Referring IPs report, while I see the screenshots from the Referring domain report which obviously leads to the faulty conclusion.
In real life, each domain can have more than one unique IP address. If we would show only one IP address per domain that would be incomplete. Secondly, we have no discrepancy in our reports. In the Referring Domains report we show one IP per domain. In the Referring IPs report, we show all domains per unique IP. So the number of unique IPs that are shown on the Overview report is equal to the number in the Referring IPs report. It would be incorrect to download the info from the Referring Domains report and filter it.
Regarding the data collection: you have a great point that we collect data differently. Yes, we do, but it doesn’t make our data bizarre and misleading, as you’ve claimed in your headline. As a data company, we think the actual numbers are, in fact, a lot less misleading than prediction-based formulas and estimates. We are very transparent about what we show on the dashboards and have a lot of tooltips with explanations. In the recent 6 months, we have grown the database, but reports haven’t really changed, so if you knew SEMrush as your employer’s competitor before, the dashboards should have been familiar.
“but it doesn’t make our data bizarre and misleading”
No it doesn’t – however the test was discussed with 3 members of the SEMRush team. That call lasted for over an hour.
No one mentioned this.
So either the SEMRush team are innocent and inherently don’t know how their own product works.
Or you sat back and allowed the deck to be stacked in your favour.
Hi Matthew, I published a comment on your blog and it’s still in moderation. Would appreciate if you approve it so we could move on discussing the study on the study’s page.
thanks Russ Jones, great analysis