
SEMRush Employee Doubles Down on Bizarre, Misleading Link Data
I’d normally let this kind of thing slide, but my integrity has been impugned (Olga Andrienko has accused me of “yellow press type headlines and incorrect data” in her comment on the original post) so I feel obligated to respond. First, let me start by why I used the words “bizarre” and “misleading” and why I stand by them. To be clear, my original post said explicitly that I did not think SEMRush was falsifying data and “I do not think SEMRush is intentionally inflating their numbers“.
What makes SEMRush’s Data Bizarre?
In SEMRush’s IP reports, they will display all the IP addresses that link to you… [click image for larger picture]

However, when you click on the domain number (in this case [1]), you land on a page with an advanced filter which shows no domains associated with that IP.
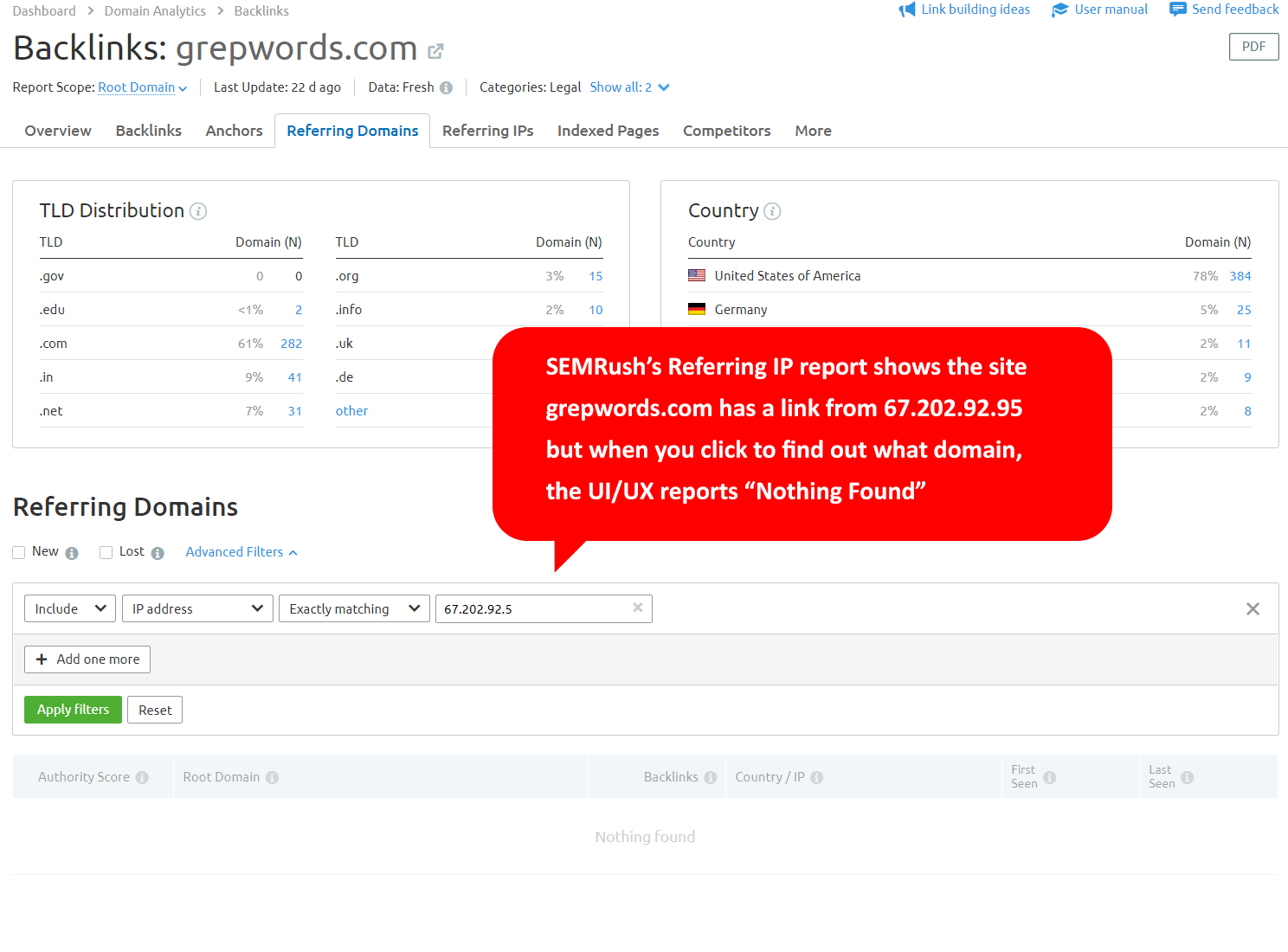
This is Bizarre. You can’t have an IP address without a domain in a link index. You just can’t.
What makes SEMRush’s Data Misleading?
SEMRush entered Matthew Woodward’s Best Backlink Checker contest which determined the size of indexes based not on root linking domains but IPs and Subnets. Unlike Moz, Majestic, Ahrefs, Webmeup and, to my knowledge, any other link index on the web, SEMRush stores every IP address they encounter for a domain over a 6 month period and report them independently. Because sites change IP addresses or use multiple IP addresses as a load-balancing method, a crawler will sometimes encounter more IPs than referring domains. This can cause their index to show more IPs than referring domains.
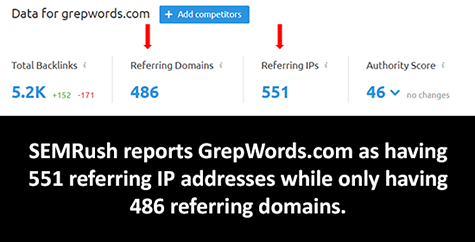
Because of SEMRush’s different collection and counting method, they destroyed the competition – not just Moz. Importantly, if I had not discovered and corrected this difference, SEMRush would still be enjoying the false narrative that their index is the largest by a landslide, and SEMRush would never correct it. But there are two possibilities. Either…
- SEMRush did not know their collection methods were different
- SEMRush did know their collection methods were different
As an aside, I knew that Moz did not collect IPs or Subnets, so I wrote a conservative model to predict these numbers and fully disclosed to Matthew in advance as to the limitations of our data. I wrote to Matthew, which he was able to put in his original post, “The [my] calculations should, therefore, be taken with a grain of salt.” This is the kind of proactive disclosure we should all make during research.
Given the two options above, it seems to me that if SEMRush did know they collect the data differently (and given their responses where they claim their method is better), then they had a responsibility to explain that essential difference and how it would make an apples-to-oranges comparison between their index and their competitors.
If they didn’t know there collection methods were different, then while this was a mistake, it calls into question what other assumptions they have made about their data when comparing their index to others and when marketing their index as the biggest or the best.
Responding to Olga Andrienko
First, let me acknowledge that she was not speaking in an official capacity on behalf of SEMRush. Here opinions are in Italics and my responses immediately follow.
- “The SEO tools industry had always been known for the respect among the members of our vast community”
I agree, and I still think it is. This is why I twice indicated that I believed SEMRush’s data was not maliciously constructed. - “yellow press type headlines and incorrect data published about us”
I believe I have defended the headline adequately above. Moreover, I published no incorrect data. - “You should have used the Referring IPs report”
I used both the Referring Domains and the Referring IPs report. The first showed the discrepancy in counts, and the second showed you had IPs that were not associated with a root linking domain (ie: “Nothing Found”). Both reports were highlighted. - “each domain can have more than one unique IP address”
Yes, and I made this abundantly clear in my article when I mentioned Round Robin DNS as an example. - “we have no discrepancy in our reports… Referring IPs report, we show all domains per unique IP.”
Yes, you did and still do. In the Referring IPs report, I can click on an IP and it will show me no associated root linking domain (ie: “Nothing Found”). This is a discrepancy. - “It would be incorrect to download the info from the Referring Domains report and filter it”
On the contrary, if you did this with any other tool, you would find the exact same number. I couldn’t rely on the referring IPs report because IPs were not and still are not adequately associated with domains in that report. - “we think the actual numbers are, in fact, a lot less misleading than prediction-based formulas and estimates”
I agree. If I provide a model, I am clear to the data partner and, as Matthew’s post indicates, I told him to take the data with a grain of salt. The important thing is knowing your index and disclosing any idiosyncrasies. - “We are very transparent about what we show on the dashboards and have a lot of tooltips with explanations”
If I had not discovered this difference in calculation, would SEMRush have proactively reached out to Matthew for a correction? - “so if you knew SEMrush as your employer’s competitor before”
I never used SEMRush’s UI for links because, frankly, until recently it wasn’t a contender. And, honestly, I don’t use most sites’ UI/UX. I just interact with their API.
Concluding Thoughts
- Don’t give data to a contest without proper disclosures.
- If you can’t give a proper disclosure because you are ignorant of your data’s differences, that is your problem.
- Don’t accuse me of “yellow headlines”.
And a Question to Olga Andrienko:
If I had not found this difference between the way SEMRush reports IPs and everyone else in the industry, would SEMRush ever have sent in a correction to Matthew?
{kind=link}
I should also point out I had an hour conversation with 3 members of the SEMRush team as I did with every other tool.
On that call we discussed the parameters of the test.
Nobody mentioned the IP thing despite talking in detail about an IP based test.
Therefore there are only 2 possibilities-
1) It’s completely innocent which also means they are unaware of their product and how it works
2) They sat back, said nothing and allowed the deck to be stacked in their favour
And despite the discovery – they initially refused to provide updated data for a fair test.
I had to “politely” convince them otherwise.
Once they have provided that data, I am going to be updating my post with the real results along with $3k of paid ad spend to correct anyones malformed opinions.