
Privacy and Accessibility: Responses to the #privacy initiative
There has been quite a bit of response to the #privacy (http://www.poundprivacy.org) initiative and I am thankful for all who have supported it and taken time to blog about it, link to it, or mention it among your friends and colleagues. The response has been very supportive. (SEOMoz, Google Inside, WebDevForums (15000+ Members), Syndk8 (6500+ Members) and many more.) If this is to be successful, it will require as much support as possible. There are a handful of responses which I believe should be discussed out in the open. I will try to cover the questions which have been raised about the standard as well as I can.
(1) Doesn’t adding #privacy to a search flag it as “This is a really interesting search! Hot Stuff Here!” (http://michaelzimmer.org)
Should you allow a police officer to search your car, just so you don’t look suspicious? No. Asserting your right to privacy, in any situation, can draw attention. Unfortunately, right now, you do not even have the ability to decide whether or not to assert your right to privacy. If someone were able to get access to #privacy searches (ostensibly through packet sniffing, as the #privacy standard would require that server logs be purged of this data), yes it may draw attention. We believe that creating more options, in this case #privacy, is far better than the single option that users have now.
(2) What about server logs?
Because the #privacy initiative prevents search engines from storing the query + ip together, it would be required that server logs be purged or prevented from storing this data together.
(3) The internet is overtly public, you should just accept it.
Admittedly the internet is a public place. There is, however, a huge difference between an activity being public, and how that activity is logged, organized, and reported.
For example, as I walk down the street, I am in a public place and, presumably, all my actions are public. However, I feel free to mutter things to myself in the assumption that it is far too difficult for an unwanted third-party to access my information. If there were video cameras with amplified microphones along the street, and a member of the press walking by me at all times with a notepad, I would not behave the same – even though I am in just as public an environment as I was before. It is not the “public vs private” that matters as much, as how well organized and accessible my public information has become. This information was previously de-facto private, although publicly offered.
The problem with search engines is that the video cameras, microphones, and member of the press happen all behind the scenes. The anonymity expected by the user is simply not present. That anonymity is further decreased because the information is stored over time in great deal, allowing for information patterns to be developed on such a great level that an individual could never begin to understand the privacy implications of a single search query.
(4) “It propagates the simplistic “opt-in/opt-out” thinking that the US marketing industry has been promulgating for decades. Look where that thinking has taken us.” (http://www.emergentchaos.com)
Unfortunately, Search Engines are corporate entities which can determine the “price” of using their services. I believe that, once again, having a choice to opt-in, and opt-out, and at least knowing that there is something to opt-out of at all, is better than the current paradigm.
(5) “Implementation is left as an exercise for the search engines”. (http://www.emergentchaos.com)
Yes. In the same way that you trust a third-party-proxy to protect you, you must trust the search engines in this case. If you do not, go install a third party proxy, turn off cookies, and miss out on a lot of good the web has to offer.
(6) “It defaults all queries to opt-in”. (http://www.emergentchaos.com)
I would love it if people had to explicitly opt-in to tracking. Unfortunately, this is not the direction that the web has gone regarding privacy. For example, you have to opt-out with robots.txt, nocache, or noindex.
(7) “For some remarkable reason, no search engine has actually bothered to comment on the proposal.” (http://www.emergentchaos.com)
While no search engine has commented publically, we have been in regular contact with multiple top-search engines. However, I cannot comment on the progress of the standard to date with these engines.
(8) “It will be prone to user error”. (http://www.emergentchaos.com)
Of course it will. Which makes it, like every other solution ever made for anything, not perfect.
Discussion:
The real issue at hand is the privacy -> accessibility continuum. The graph below explains.
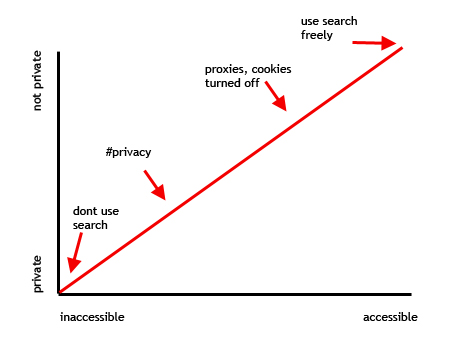
2: Use Proxies, Turn off Cookies: Strong privacy, minimal accessibility (user knowledge, administrator privileges on accessing computers, cell phone and PDA searches, user error, etc.)
3: Use Search Freely: No privacy, complete accessibility.
We are proposing a 4th option. It falls somewhere between Using Proxies and Use Search Freely (see the graph). It is certainly not a strong a protection as some of the other solutions available but…
A. It is free to use
B. Works on any computer, pda, cell phone, WEB TV, or whatever else you use to access the internet.
C. Short and easy to remember
In no shape or measure did I ever expect #privacy to answer the search privacy debate. On the contrary, #privacy offers another solution in the search arena that is far more accessible than the options currently available.
I urge you to continue to support #privacy at http://www.poundprivacy.org – Thank you again to those who continue to support the new standard.
{kind=link}
Privacy 🙂