
Googlebot Indexing Emails, What Will They Think of Next?
Sometimes I have to ask – Google, what the hell are you thinking? Googlebot has a way of sneaking into almost every crevice of the web (it is quite remarkable in all actuality), but in the process seems to indiscriminately publish items of all kinds of nature.
While I am certainly not surprised, I recently came upon Google’s indexing of the .eml file extension. This is most commonly used for archived emails. As you can plainly see, Google is now indexing and displaying these files.
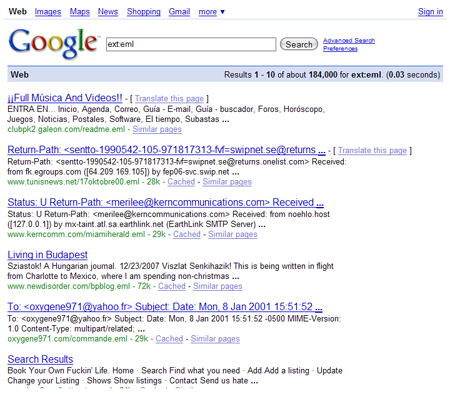
{kind=link}
In a way, I am not too surprised at this, either: it is a text format, and so it it just indexing it…
The content type for such files are typically text/plain and it is the content type, rather than the extension, that search engines will base their indexing on. This allows web developers to create their own extensions as they want. For example, I could create a plain html file called example.google (i.e. a “google” extension), but from what I can tell, it is no different in its treatment to example.html.
Hence, someone could create .eml extensions for something else, not emails.
I think the reasons these emails are being indexed is that they are likely linked to from elsewhere. If that is not the case, then that is odd indeed, else how would they know about these files?
Editors Note: You raise some good points. My immediate question, however, is whether all web-accessible, text-based content should be indexed. Google claims to hold itself to rigorous ethical standards, and I am hard-pressed to believe that they are honoring the intent of internet users by indexing the .eml extension. I like to think about it like this: Lets say GoogleBot is a shopper in a Mall – an ostensibly public place where everyone is welcome. GoogleBot is trying to make a map of the mall so people can get around more easily. It enters all of the shops and wherever doors are open, like the public restrooms. Eventually, though, it starts opening up doors inside the stores. Some are locked – doors to cash registers, doors to supply closets. Sometimes, though, they are not unlocked – doors to changing rooms, doors to bathroom stalls. If GoogleBot has an easy way of chosing not to go into these internal rooms which reasonably hold little-to-no public-information, is it unethical to keep peering in? I believe so.
I understand what you are trying to say, but how is google to know from the *content type of text/plain* (not the extension of the page) that this is an email, *or* that this is an email *not* to be indexed?
If there are no instructions saying don’t index it, then it has nothing to go on. Maybe it was linked to because people wanted it to be visible? Maybe it was an example of an email that the content producer wanted referenced?
Anything on the web is indexable (viewable) if a search engine (or user) can get to it. To stop it, it needs robot rules, etc. Else, search engines try to guess, and guesses will go wrong…